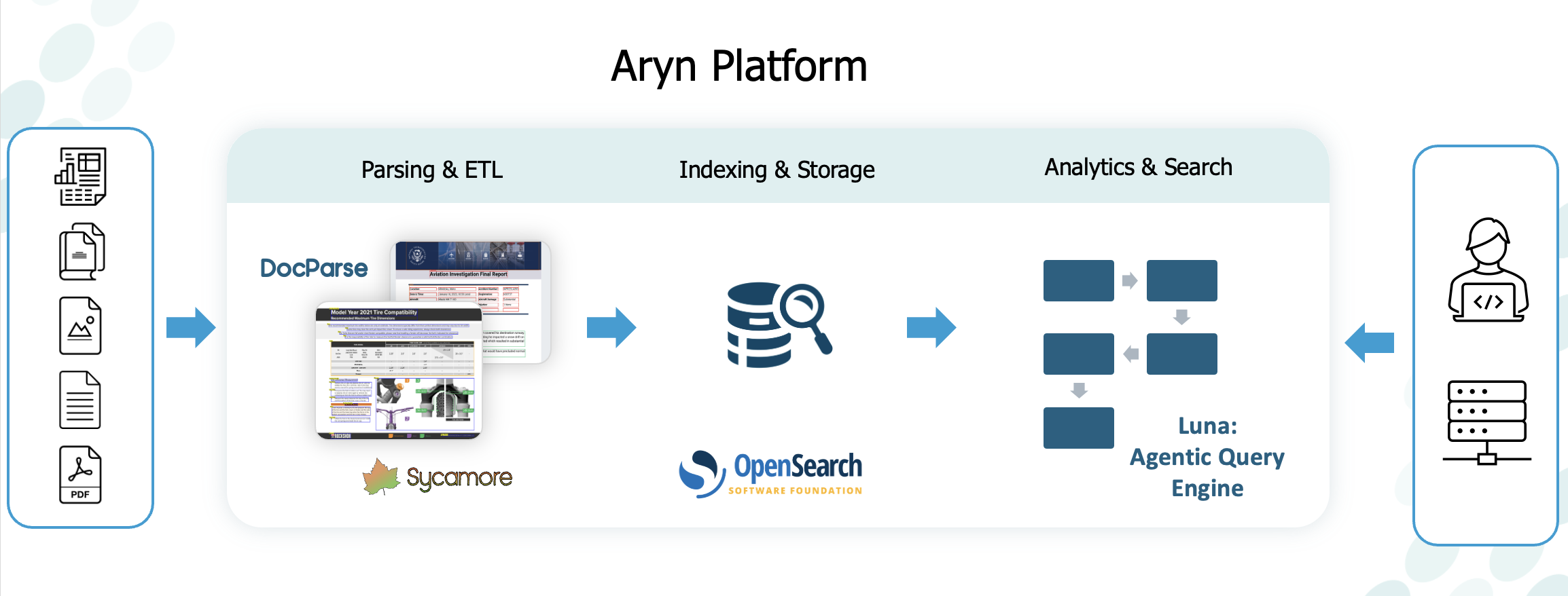
Loading and enriching documents
Aryn stores collections of documents in a DocSet, short for “Document Set.” Think of it like a table in a data warehouse, where you can store a set of information that you can query. When adding a new document to a DocSet, Aryn will process it and add it to internal vector and keyword indexes in an OpenSearch backend. You can specify properties (metadata) to extract and store from the documents in a DocSet, which are key/value pairs that provide additional information for the Aryn query engine to use. As a side note - we’re big OpenSearch fans and helped bring it to the Linux Foundation! When Aryn processes a document, it uses DocParse for segmentation, OCR, table extraction, image summarization, chunking, and more. If you have specified properties (metadata) to extract from your documents, Aryn will use an LLM of your choice to do so. Aryn can ingest 30+ document formats, including PDF, Microsoft Office, and more. If your workload requires custom document ETL, such as more advanced metadata extraction, data transforms, data cleaning, or a custom chunking strategy, you can utilize the open source Sycamore document ETL library. It enables you to write custom ETL pipelines in Python, configure the LLM service to use for metadata extraction, uses the same DocSet abstraction as Aryn (surprise!), and it runs on Ray so it can scale to thousands of documents. Sycamore can load an Aryn DocSet as a final step. Once your documents are processed and loaded in a DocSet, it’s time to query them!Deep Analytics
Aryn has an agentic query engine that combines GenAI reasoning with database and LLM-based query operators to run analytics and complex queries on your DocSets. We call this Deep Analytics, because you can iteratively query and navigate through your unstructured data with analytics questions. Aryn provides a Workspaces UI purpose-built for Deep Analytics, and you can build applications with our APIs using the Aryn SDK. The platform has three main operations for running Deep Analytics:- Creating query plans: Aryn takes a natural language question or command and creates a query plan using its agentic query planner. The planner uses its understanding of the available operators, document properties/metadata, and other context to generate a high quality plan. Aryn has a mix of database-style operators, such as filter, aggregate, and search, alongside LLM-based operators like LLM-Extract and LLM-Filter. The LLM-based operators utilize AI to reason over data in real-time during a query, which extends the ability of Aryn to better semantically understand documents.
- Editing query plans: Aryn separates the generation and execution of query plans, so you can inspect the plan and edit it, if necessary. Possible reasons to edit a plan include tweaking the metadata used in a filter operation, choosing to run a different query because an LLM-based operator would process too much data (latency and cost), or correcting an incorrect operator, or making other minor adjustments. You can manually edit these plans, or use the Aryn Workspace UI to change them with natural language commands.
- Running query plans: Once you have your desired plan, it’s time to run your query! Aryn executes queries on a scalable backend for good performance. The output of your query is also a DocSet, which can include a list of documents, additional extracted properties/metadata, natural language summaries, and obviously, the result. If you want to run a subsequent query on this output, you can save the output as a bookmark (available in the Workspace UI). This will save the output for the duration of your Workspace session, and you can specify a Bookmarked DocSet in your queries.