Introduction
In this tutorial, we will walk through an example of using DocParse to extract structured metadata from a document. This lets you combine document parsing and semantic field extraction with a single API call. We will be working with a sample insurance document that contains information about a workers compensation reinsurance submission.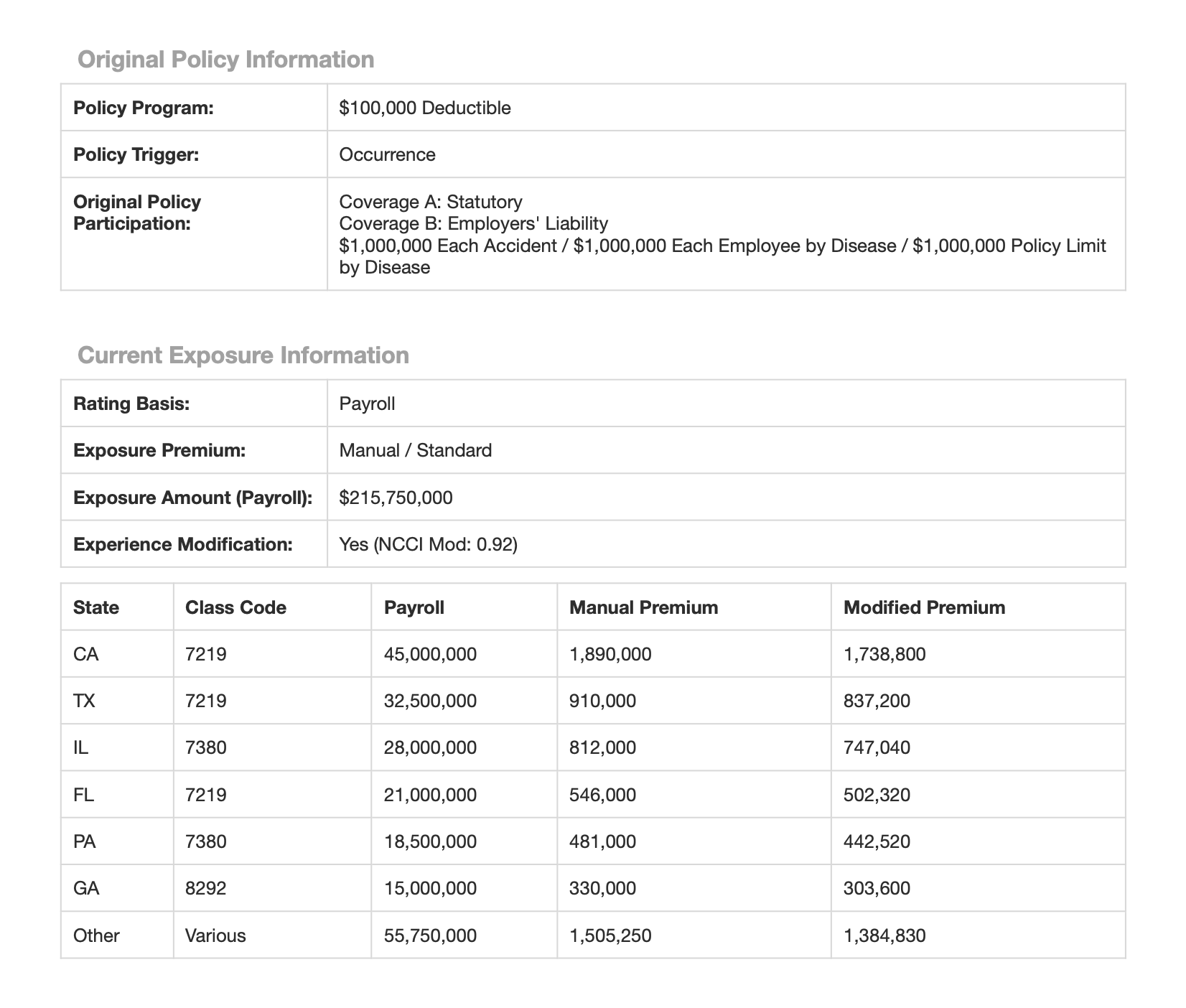
Prerequisites
- Get your free Aryn API key by signing up on the Aryn Console at app.aryn.ai.
- Open up the follow-along Colab notebook and copy in your API key by clicking the key icon on the leftmost side of the screen. Then, click the “+ Add new secret” button in blue on the left hand side of your screen. Finally, add your Aryn API key in the value field under the name “ARYN_API_KEY”. Alternatively, you can set the API key as an environment variable and follow along locally instead of on Colab.
- Download the sample document or have your own handy.
Schemas
Property extraction is based on a schema that defines what to extract. A schema is a list of properties, each of which have a name, a type, and optional fields like a description, default value, and example values. These fields are used to guide the LLM on what to extract. While you can provide the Schema as a dictionary, the Aryn SDK also includes a Pydantic model that makes it easy to work with schemas. For example, the following code creates a schema with two fields:Step 1: Simple Property Extraction
You can extract all of the fields a schema by specifying the schema underproperty_extraction_options.
table_mode to standard. This ensures that we can extract properties that are present in tables, such as the Submission Contact Email.
In the output, you will see a separate top-level key “properties” that contains the extracted properties. For this document, you should see something like the following:
Step 2: Extracting Nested Data with Arrays
It’s common to want to extract multiple records from a single document, each of which has a similar schema. For example, in the sample document, the current exposure information is broken out by state in a table on page 2. You can extract all of these entries with DocParse by specifying a schema containing an array of objects, like the following:ARRAY, and you specify the type of each element in the Array as the item_type. In this case, the item type is an object with the fields you want to extract for the individual exposure records. The result of running this script is the following: