Introduction
In this example, we’ll use DocParse to extract images from a battery manual. We’ll go through the important code snippets below to see what’s going on. Let’s focus on the following code that calls the DocParse partition API to parse the manual, extracting its embedded images, inline text, and tables:partitioned_file, you’ll notice that it’s a large JSON object with
details about all the parsed elements in the PDF (checkout this page to understand
the schema of the returned JSON object in detail). Below, we show the first few elements of
partitioned_file:
Extracting the Image
Below, we show anImage element that contains the information about the first
schematic image in the file. You see key properties of the image, including its bounding box
(which indicates the coordinates of the image in the page) and
a base64 encoded binary representation of the image.
Output Image
You can then process this JSON however you’d like for further analysis. For example, let’s use the Pillow Image module from python to display the extracted image on its own.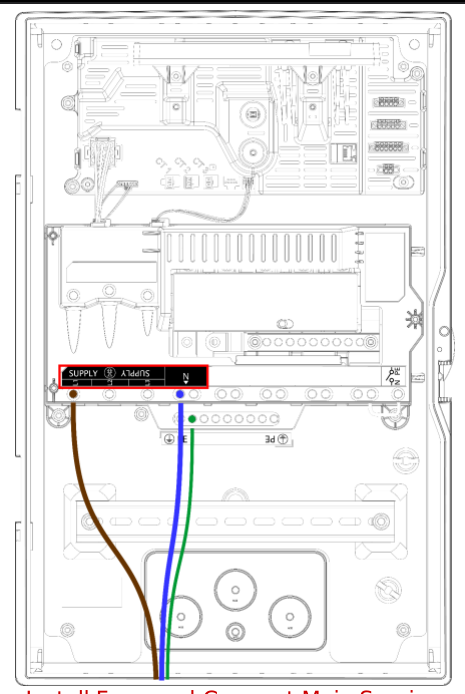
Captions
If you want to associate captions with the images, you can reprocess the file with theassociate_captions parameter within image_extraction_options set to True.
associate_captions parameter, you’ll notice that the image is now associated with a caption, as seen below.
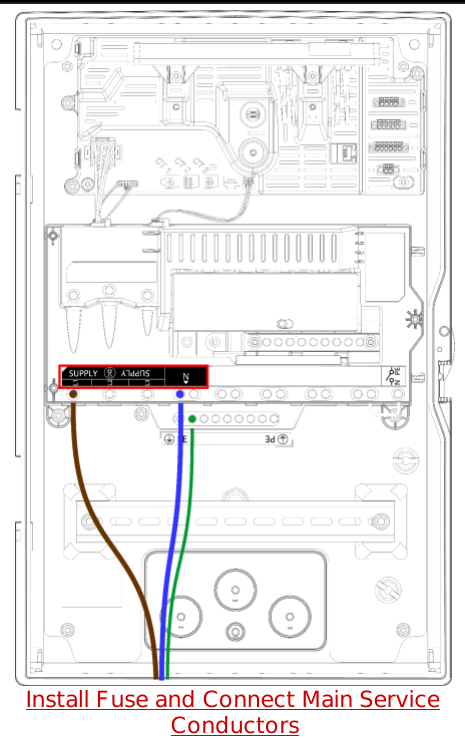
caption field of the element.