Introduction
In this tutorial, we will walk through an example of using DocParse to extract structured metadata from a document via the Aryn DocParse UI. We will be working with a sample insurance document that contains a workers compensation reinsurance submission.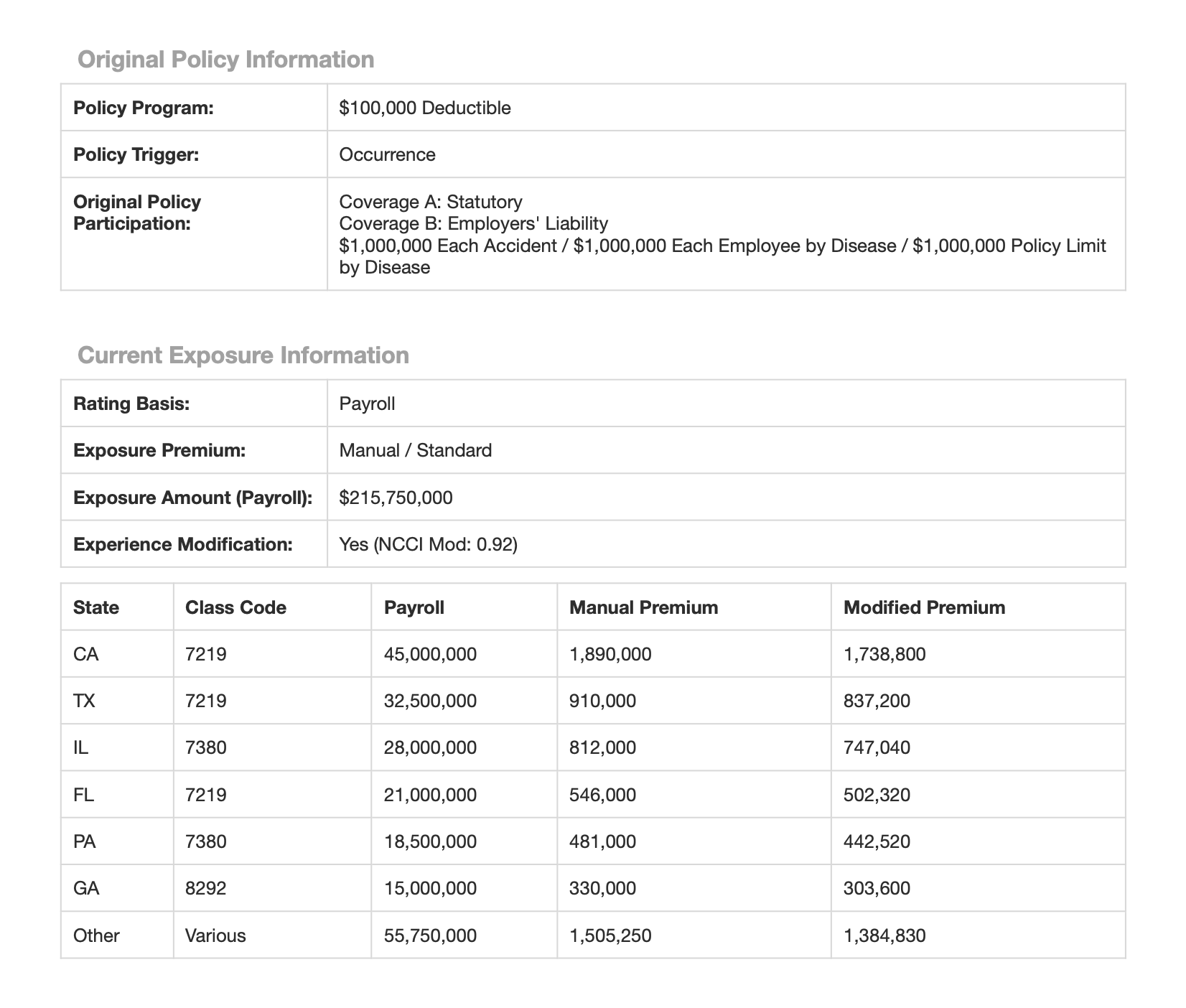
Prerequisites
- Get your free Aryn API key by signing up on the Aryn Console at app.aryn.ai.
- Download the sample document or have your own handy.
Step 1: Defining a Simple Schema
Once you have logged into the Aryn console, load the document you downloaded into the DocParse Playground. To define properties, click on the “Configure Schema” button on the right-hand side of the page.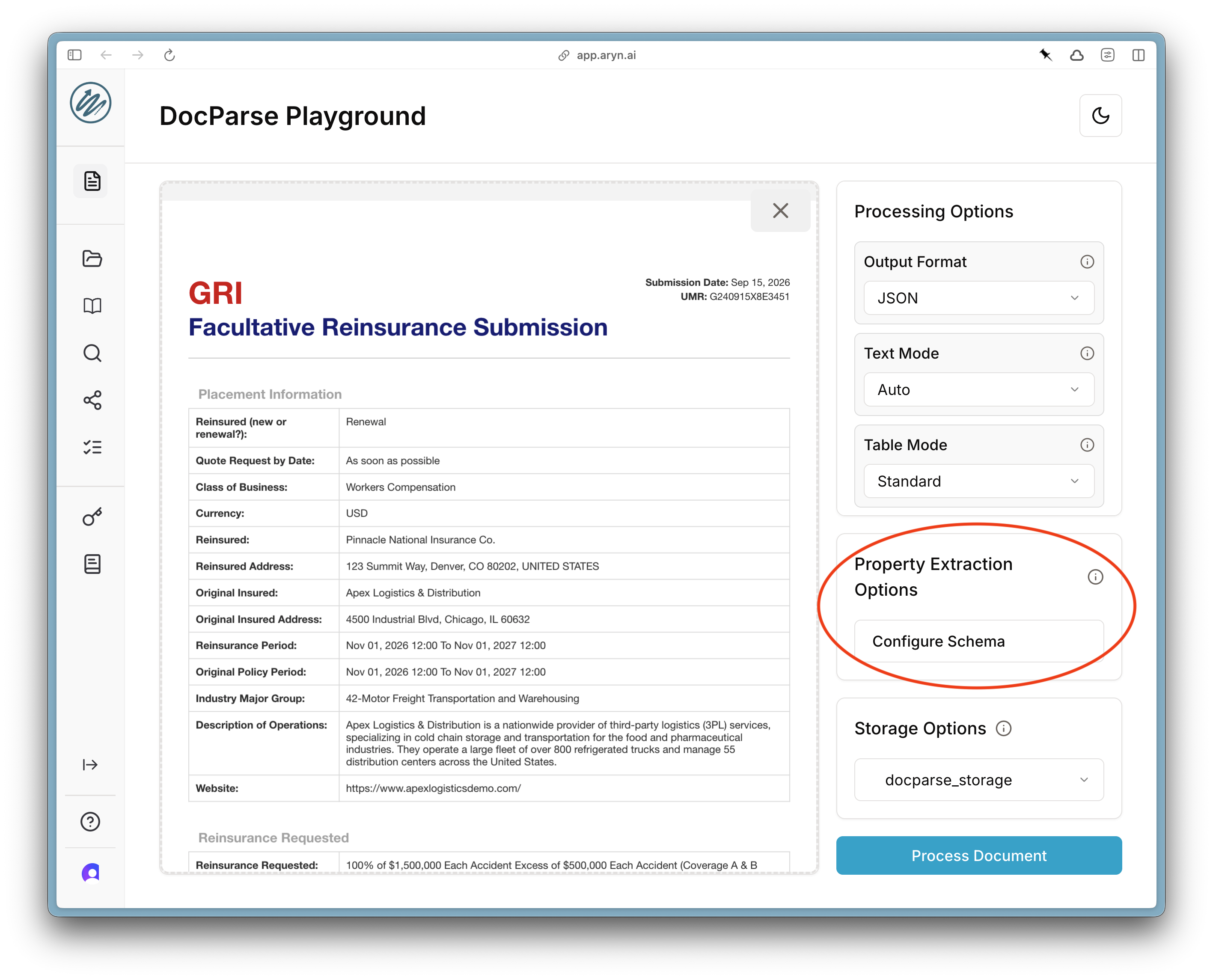
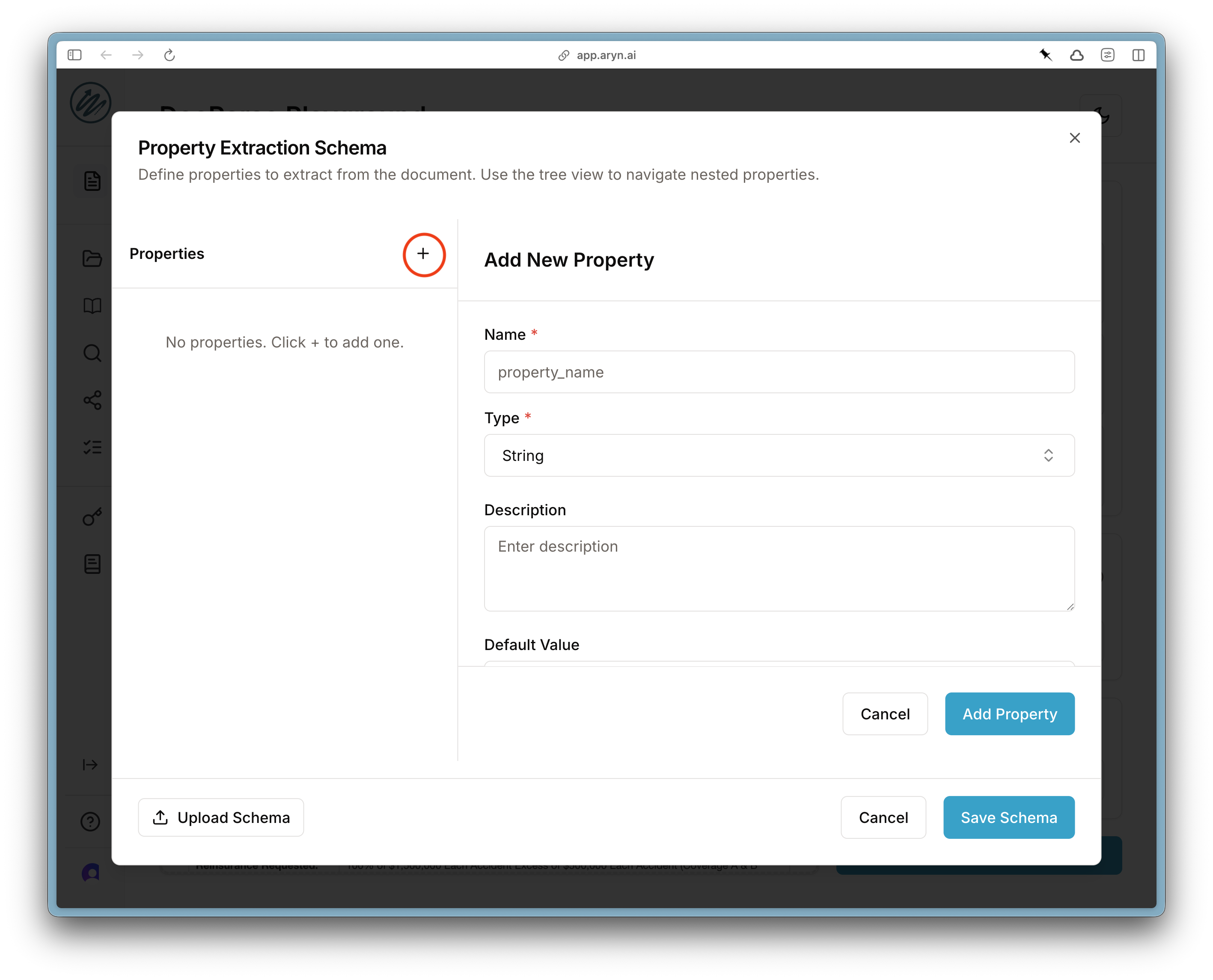
+ button to add a property. For each property you can specify the name and type of the property, as well as an optional description, default values, and examples.
Step 2: Extracting Nested Data with Arrays
It’s common to want to extract multiple records from a single document, each of which has a similar schema. For example, in the sample document, the current exposure information is broken out by state in a table on page 2. You can extract all of these entries with DocParse by specifying a field of typeArray.
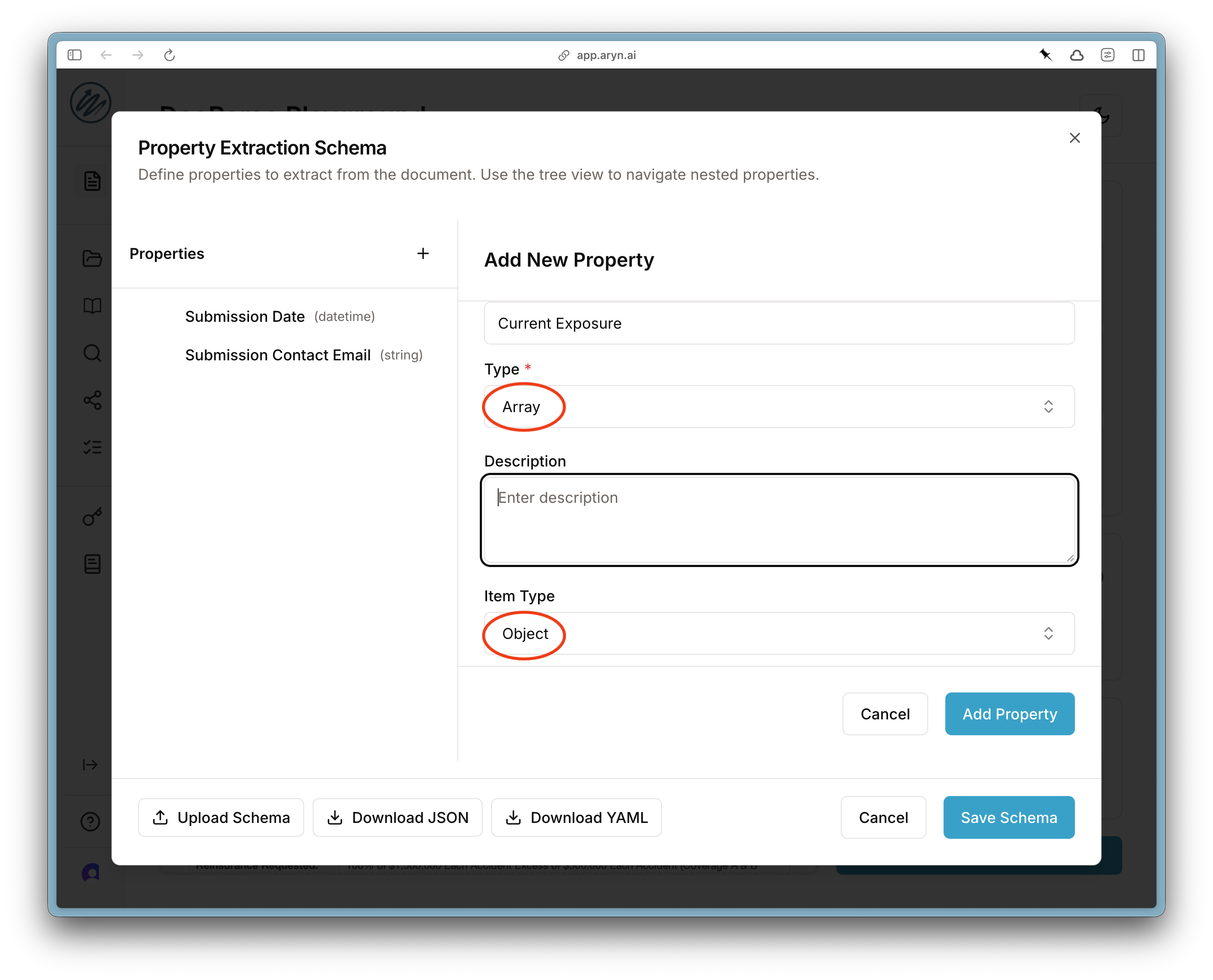
Object. Then, scroll down and specify the properties of each Array element.
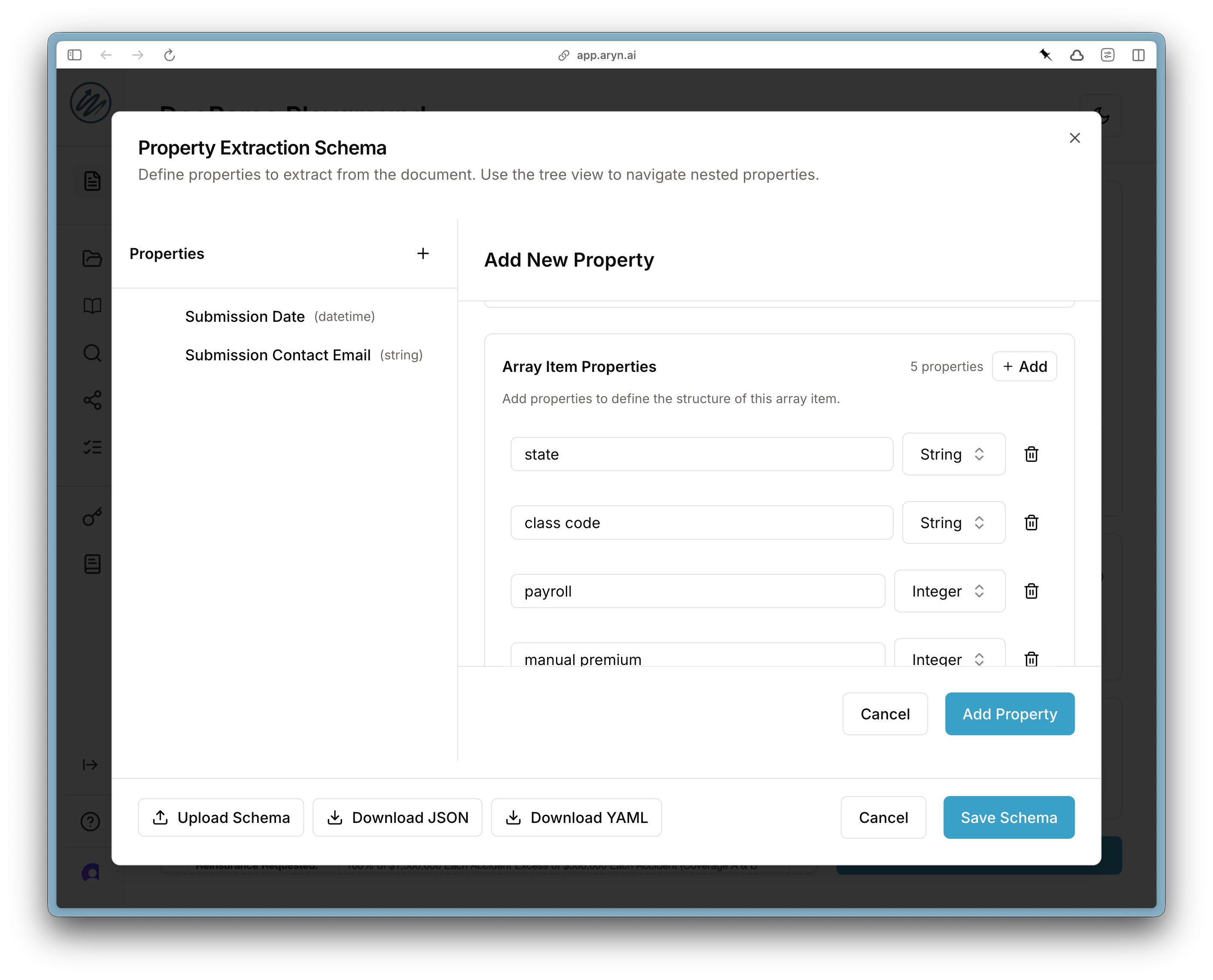
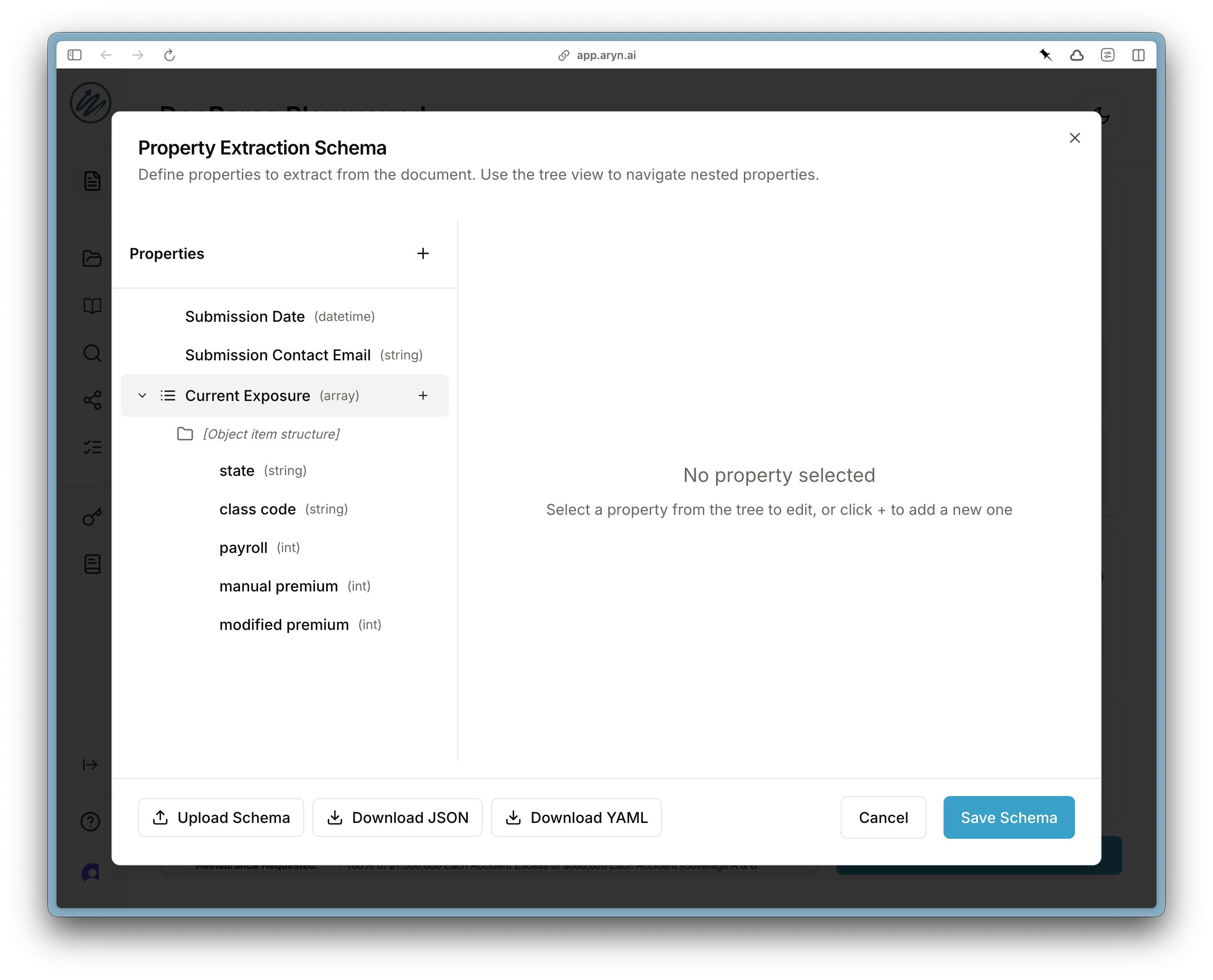
Save Schema and then Process Document to perform the parsing and extraction.
Step 3: Review Results
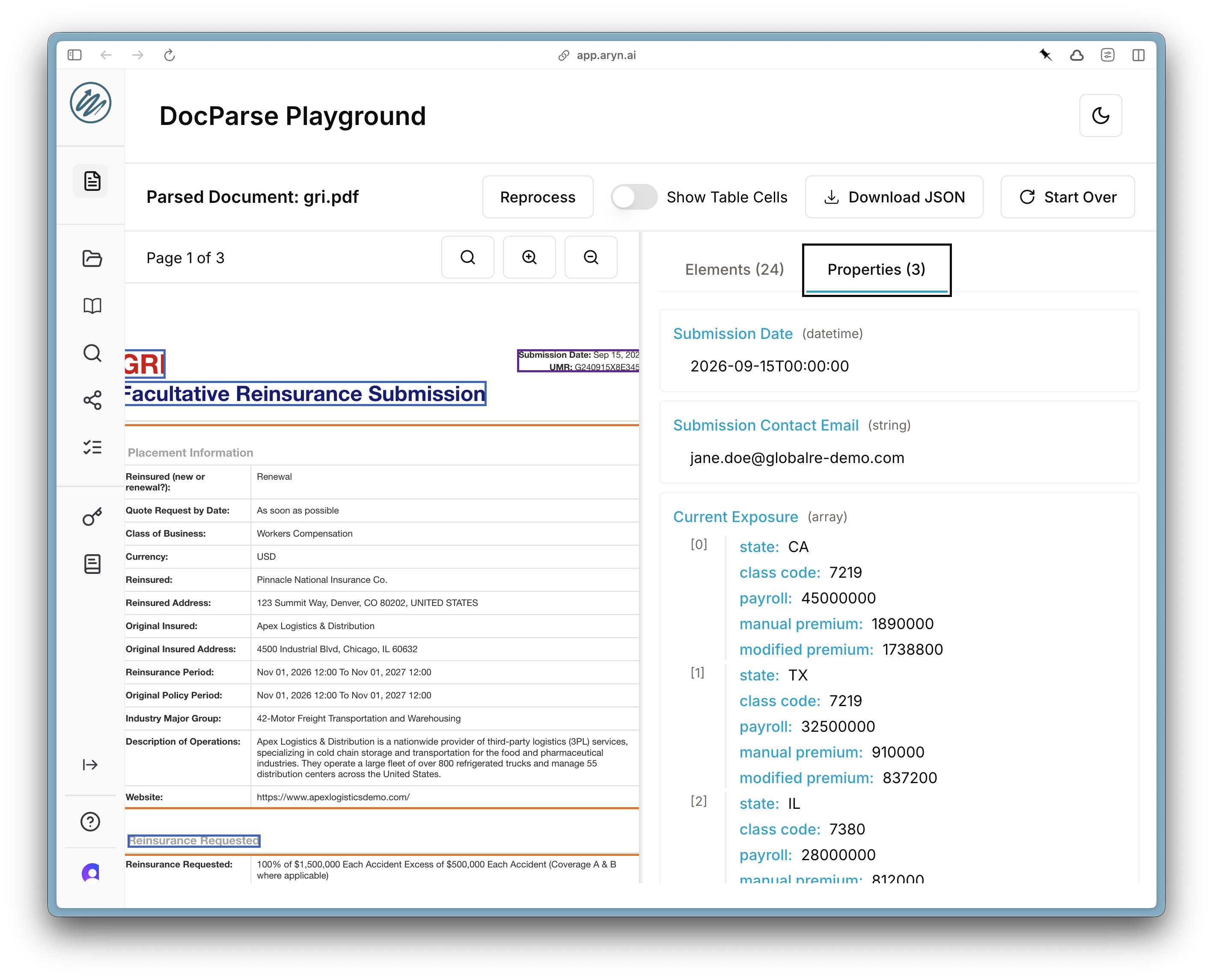
After DocParse has finished processing, you can review the results. Select the “Properties” tab on the right-hand side to look at the extracted properties.